声明:本文来自于微信公众号 量子位(QbitAI),作者:白小交,授权站长之家转载发布。
无需用户提示,AI就可以识别万物!
而且精度更高、速度更快。
刚刚,IDEA研究院创院理事长沈向洋官宣IDEA研究院最新成果:通用视觉大模型DINO-X。
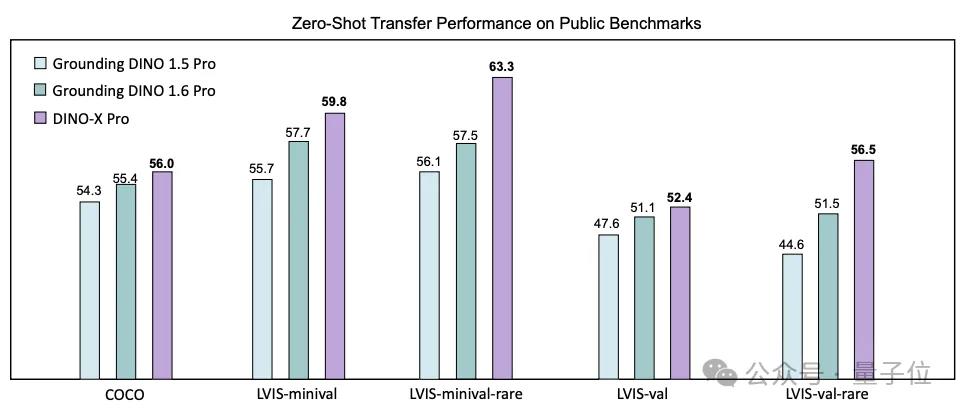
它实现视觉任务大一统,支持各种开发世界感知和目标理解任务,包括开放世界对象检测与分割、短语定位、视觉提示计数、姿态估计、无提示对象检测与识别、密集区域字幕等。

这背后得益于,他们构建了超过一亿高质量样本的大型数据集Grounding-100M。
与之前DINO家族中Grounding DINO1.5类似,DINO-X 也分为DINO-X Pro模型和DINO-X Edge模型。
前者可为各种场景提供更强的感知能力,后者经过优化,推理速度更快,更适合部署在边缘设备上。
实验结果表明,DINO-X Pro 模型在 COCO、LVIS-minival 和 LVIS-val 零镜头物体检测基准测试中分别获得了56.0AP、59.8AP和52.4AP 的成绩。
尤其是在 LVIS-minival 和 LVIS-val 这两个罕见类别的基准测试中实现新SOTA——
分别获得了63.3AP 和56.5AP 的成绩,都比之前的SOTA性能提高了5.8AP。
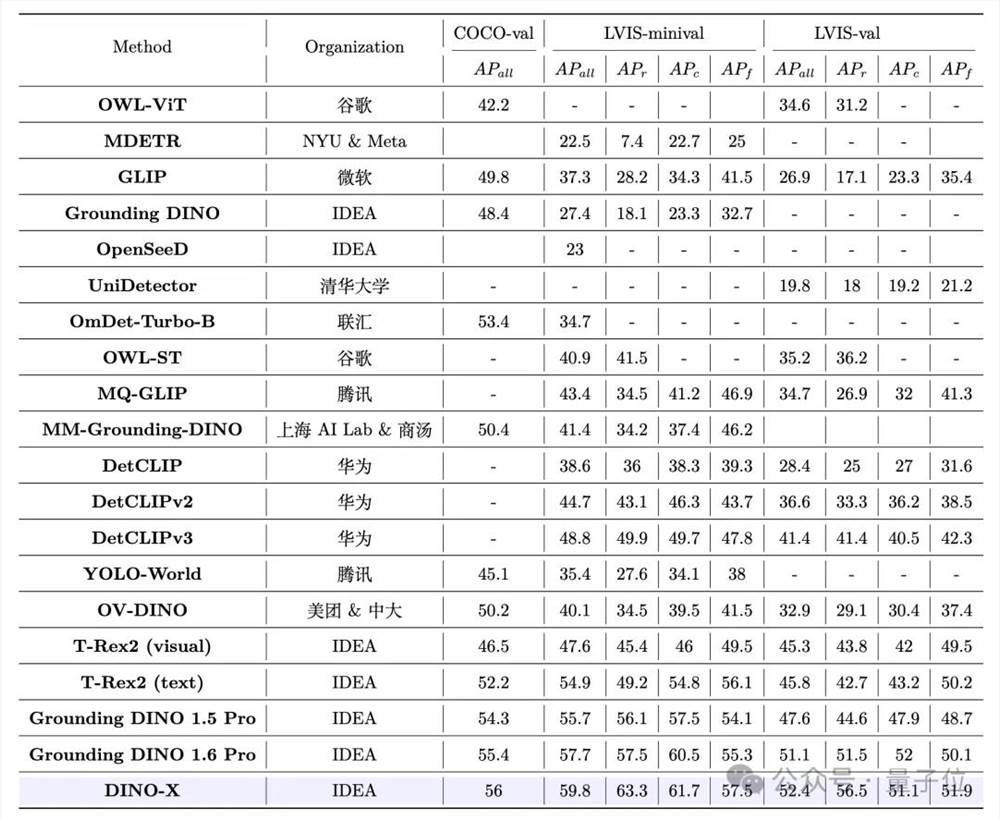
这一结果表明,它在识别长尾物体方面的能力有了显著提高。
在开放世界,AI识别万物
总结来看,DINO-X主要有四个方面的特点。
首先就是全面检测,几乎可识别所有物体。DINO-X称得上目前业界检测最全的通用视觉模型,甚至无需用户提示。

然后是泛化和通用性。在面对未见过的物体或环境时,模型仍能保持高水平的检测性能。
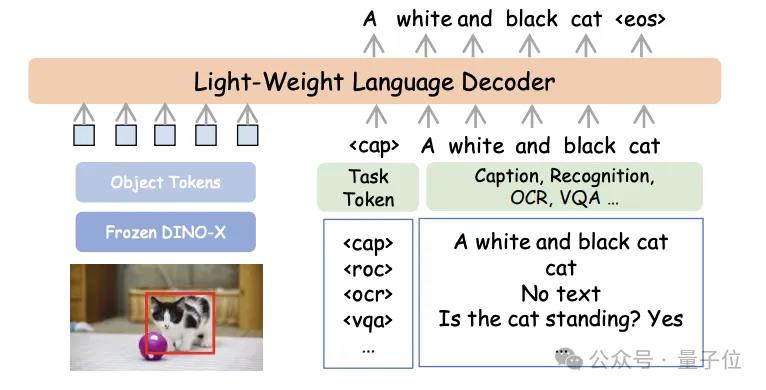
细粒度目标理解:DINO-X通过统一多个视觉任务,实现了多样化输出,包括边界框、分割掩码、关键点和描述文本,提升了模型在复杂场景下的理解能力。

多任务感知与理解:DINO-X整合了多个感知头,支持包括分割、姿态估计、区域描述和基于区域的问答在内的多种区域级别任务,让感知到理解逐步成为了现实。

长尾目标检测优化:为了支持长尾目标的检测任务,DINO-X不仅支持文本提示和视觉提示,还支持经过视觉提示优化的自定义提示。
跟之前的版本 GroundingDINO1.5Pro 和 Grounding DINO1.6Pro相比,此次通用视觉大模型DINO-X 进一步增强了语言理解能力,同时在密集物体检测场景中表现出色。

如何做到?
DINO-X可接受文本提示、视觉提示和自定义提示,并能同时生成从粗略的表示(如边框)到精细的细节(包括遮罩、关键点和对象标题)等各种输出。
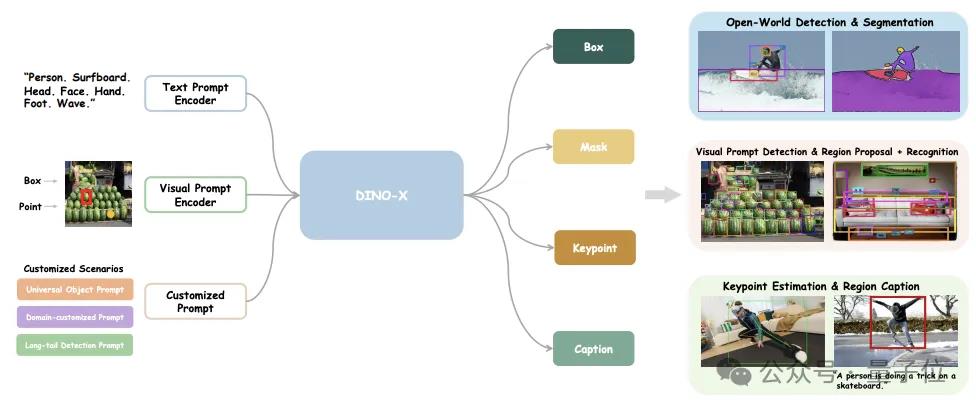
DINO-X Pro的核心架构,与Grounding DINO1.5类似,利用预先训练好的 ViT 模型作为主要的视觉骨干,并在特征提取阶段采用了深度早期融合策略。
但不同的是,他们扩大了DINO-X Pro在输入阶段的提示支持,除了文本,还支持视觉提示和自定义提示,以满足包括长尾物体在内的各种检测需求。
而对于DINO-X Edge版本,他们利用 EfficientViT作为高效特征提取的骨干,并采用了类似Transformer编码器-解码器架构。
此外,为了提高 DINO-X Edge 模型的性能和计算效率,他们还对模型结构和训练技术做了几个方面的改进。
更强的文本提示编码器,采用了与pro模型相同的 CLIP 文本编码器。
知识提炼:从 Pro 模型中提炼知识,以提 Edge 模型的性能。具体来说,团队利用基于特征的蒸馏和基于响应的蒸馏,分别调整Edge模型和 Pro模型之间的特征和预测对数。
改进FP16推理:采用浮点乘法归一化技术,在不影响精度的情况下将模型量化为 FP16。
拥有了对开放世界的视觉感知
DINO-X的万物识别能力,让其拥有了对开放世界(Open World)的视觉感知,可以轻松应对真实世界中的众多不确定性和开放环境。
IDEA研究院创院理事长沈向洋提到了具身智能、大规模多模态数据的自动标注、视障人士服务等这几个场景。
对具身智能而言,开发环境感知和理解是核心能力,这其中的视觉感知更是机器和物理世界交互的基础。近期,聚焦人居环境具身智能核心技术攻关的福田实验室正式挂牌,该实验室正式由IDEA研究院与腾讯合作组建,致力于打造最前沿的具身智能创新平台。
多模态模型通常需要处理大量的图片并生成图文对,而仅依靠人工标注的方式不仅耗时、成本高,而且在面对海量数据时难以保障标注的一致性和效率。DINO-X的万物识别能力,可以帮助标注公司快速完成大批量的高质量图像标注或者为标注员提供自动化的辅助结果,从而降低手工标注的工作量。
视障人士独立性和生活质量的提升对信息获取与感知等方面有着极高的要求,DINO-X的万物识别能力恰逢其时地为助盲工具开发带来福音,为视障人士的未来生活带来美好希望。
在自动驾驶、智能安防、工业检测等领域,DINO-X使得系统能够应对各种复杂场景,识别出传统模型难以检测的物体,为产业升级和社会发展注入新的活力。
IDEA研究院一系列视觉大模型,为解决业务场景现存的小模型繁多、维护迭代成本高昂、准确率不足等问题,提供了可行的方案。
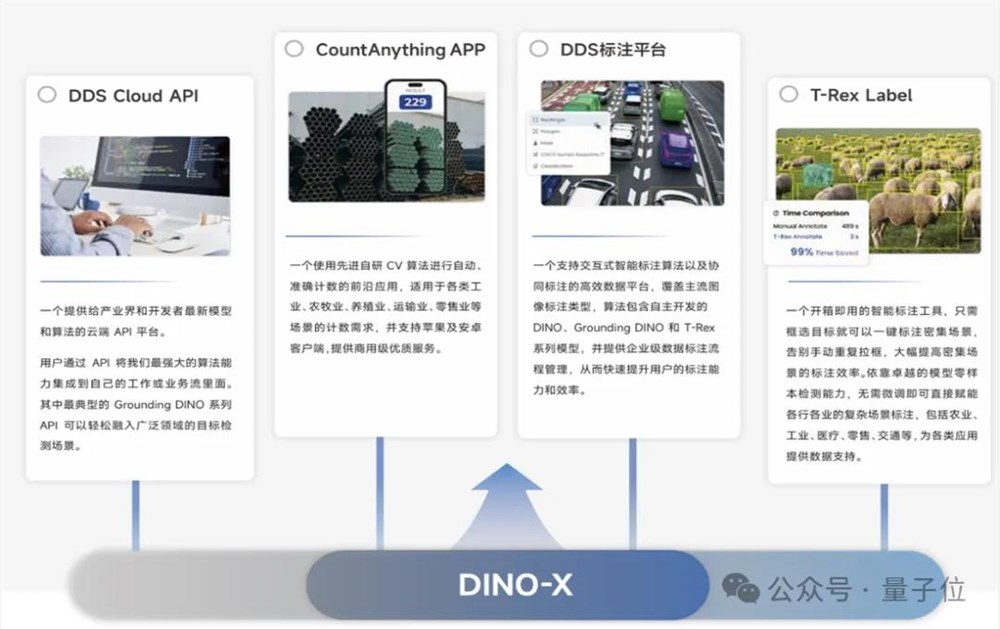
△Dino-X基座大模型零样本检测能力,为广大中小企业客户提供便捷高效的计数和标注工具
目前,IDEA研究院与多家企业联合开展视觉大模型及应用场景的探索研究工作,在视觉大模型的落地方面取得了实质性进展。
一方面,有别于市场上的以语言为基础的多模态大模型基于全图理解的方法, 通过在物体级别的理解上加入语言模块优化大模型幻觉问题。
另一方面结合自研的“视觉提示优化”方法,无需更改模型结构,不用重新训练模型,实现小样本下的场景化定制。
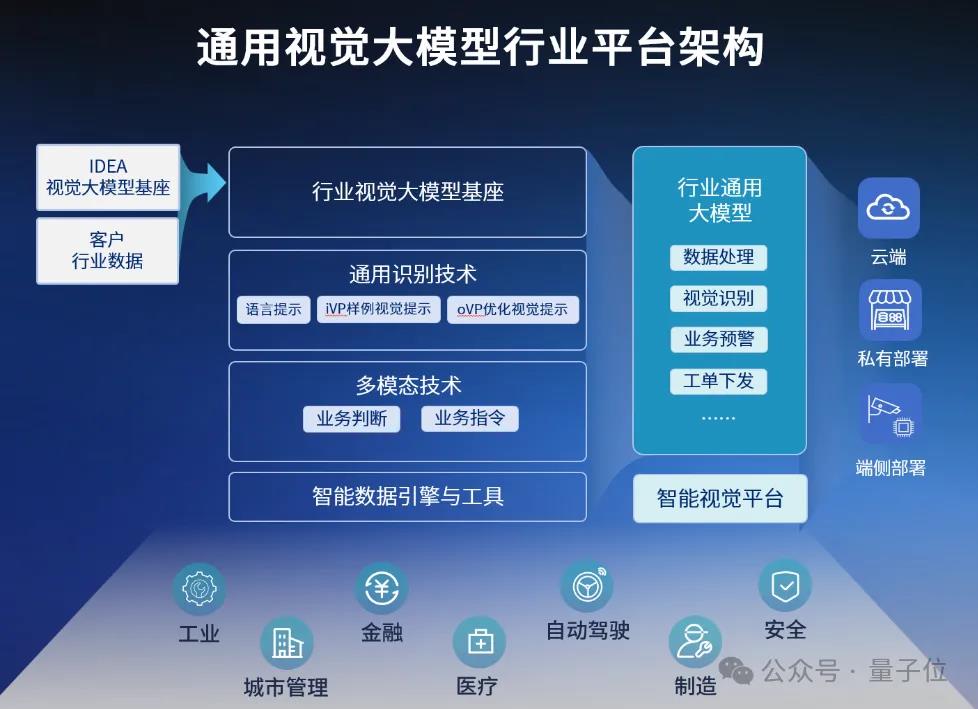
△IDEA研究院通用视觉大模型行业平台架构
论文链接:https://arxiv.org/abs/2411.14347
官网链接:https://deepdataspace.com/home