声明:本文来自于微信公众号 量子位 (ID:QbitAI),作者:克雷西 ,授权站长之家转载发布。
月之暗面和清华KVCache.ai团队的最新论文,首次揭秘了Kimi背后的推理架构!
要知道Kimi是国产大模型的当红炸子鸡,火到可以说从来没缺过流量,甚至还经常出现过载。

而随着论文的发布,这泼天的流量到底如何被Kimi接住的问题,也有了答案。

Kimi背后的推理架构名叫Mooncake(月饼),主要特点是采取了分离式的设计方案。
而且,Mooncake在设计之时就考虑了可能出现的大流量场景,并针对这种情况专门研发。
在模拟场景下,Mooncake最高能带来525%的吞吐量增长,实际场景中也能多处理75%请求。
另据月之暗面工程副总裁许欣然的一篇知乎文章介绍,Kimi有80%以上的流量,都是由该系统承接。
从KV缓存出发,建造分布式系统
整个Mooncake系统设计的核心,是围绕着KV缓存展开的。
(KV缓存用于存储键-值对(Key-Value Pairs),主要优势在于可以简单高效地访问和检索数据,在大模型当中可以提高推理速度并减少计算资源消耗。)
之所以这样做,是因为团队预计KV缓存的容量会长期保持高位,因此围绕KV缓存进行优化十分必要。

从结构上看,Mooncake由全局调度器(Conductor)、Prefill节点集群、Decoding节点集群和分布式KVCache池几部分组成,另外还有RDMA通信组件(Messenger)。
其中全局调度器是用户请求到达系统后的第一站,它负责接收请求并根据KV缓存分布和负载情况,将请求调度到Prefill和Decoding节点。
调度器在调度时需要综合考虑KV缓存的复用长度、负载均衡等因素,实现KV缓存复用的最大化。
具体到Mooncake,它采用了一种启发式的自动热点迁移策略,可以在不需要精确预测未来访问的情况下自动复制热点KV缓存块。
同时,这种动态复制热点KV缓存块的方式,也是实现均衡负载的一种重要途径。
实验结果表明,与随机调度和负载均衡调度相比,Mooncake的调度策略可以显著降低TTFT(Time To First Token,首个Token延迟),提高系统性能。
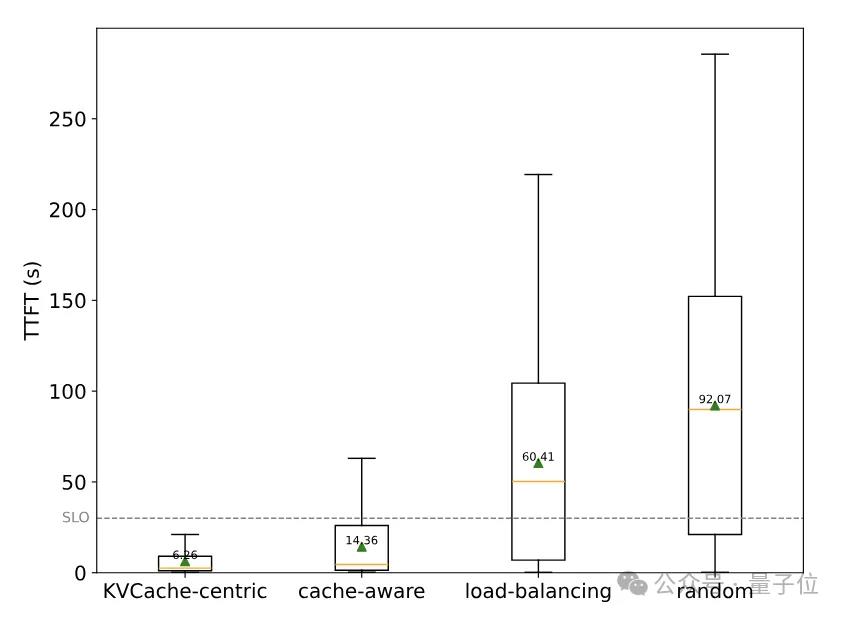
完成调度之后,任务会分别交由Prefill和Decoding节点进行运算。
Prefill节点接收到调度器转发过来的请求后,会从KV缓存池中读取缓存,执行预计算并生成新的KV缓存。
对于长上下文请求,Mooncake还会分块流水并行的方式,使用多个节点并行处理来降低延迟。
而Decoding节点除了接收调度器发来的请求外,还会收到Prefill阶段生成的KV缓存,节点会对这些缓存执行解码并生成最终结果。

这当中,大容量、高性能的KV缓存存储由缓存池提供;RDMA通信组件则凭借其高带宽、低延迟的优势,负责在不同节点之间的KV缓存传输。
除了采取以KV缓存为中心的工作流程外,Mooncake还有另一个重要特点——分离式的架构。
采取分离式架构的重要因素之一,是在于Prefill和Decoding两个阶段的计算特性差异很大。
具体来说,它们分别要对TTFT和TBT(Time Between Tokens,Token间延迟)负责。
这就导致了两者在计算复杂度、内存访问方式、并行粒度和对延迟的敏感度上都存在差异:
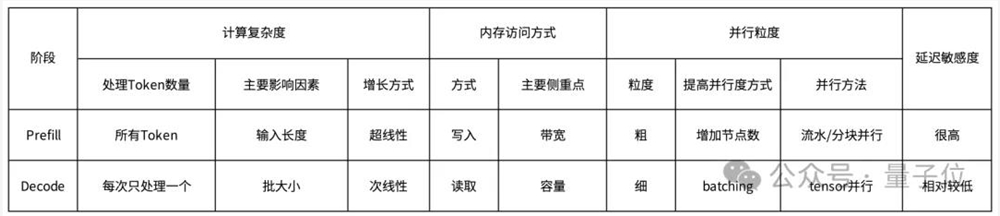
所以,月之暗面团队对GPU集群也进行了相应的拆分,以便将它们分别部署在不同节点集群上,实现资源隔离和专门优化。
另外,Mooncake中的KV缓存池也是分布式的,同时充分利用了GPU集群中空闲的CPU、DRAM和SSD资源,实现了大容量、高带宽的KV缓存存储和传输,同时也减少了闲置资源的浪费。

提前预测负载,及时拒绝超量请求
不过,即使Mooncake采用了高效的分离架构,但实际环境中的超大流量,对系统仍然是一个考验。
对此,作者也提出了新的应对策略。
在过载场景下,调度的关键是决定是否接受新的请求。
由于Mooncake采用的是分离式架构,可以采取早期拒绝策略,在Prefill阶段就根据Decoding节点的负载情况,提前拒绝请求。
Mooncake使用TTFT和TBT的SLO(Service Level Objective,服务等级目标)满足情况作为负载的度量指标。
具体的SLO要求是TTFT的90分位值(P90)不超过单个请求在空载条件下处理时间的10倍,TBT的P90值不超过5倍。
这种早期拒绝策略可以显著减少无效的Prefill计算,提高资源利用率,但同时也带来了新的问题——Prefill和Decoding节点负载的波动,导致资源利用率下降、影响系统性能。

这是由于早期拒绝策略中,系统做出请求拒绝的决策时存在滞后性,如下图所示:
- 在阶段1,Prefill节点和Decoding节点的负载都较低,此时调度器会持续接受新的请求,直到Prefill节点的负载达到上限。
- 进入阶段2后,Rrefill节点处理的请求开始进入Decoding节点,导致其负载快速上升。当Decoding节点的负载超过阈值后调度器开始拒绝新的请求,但此时Prefill节点的负载仍然很高。
- 到了阶段3,由于调度器拒绝新请求,Prefill节点的负载开始下降。但此前积压的请求正在Decoding阶段处理,节点的负载仍然很高。
- 最后是阶段4,Decoding节点的负载开始下降,因为前面的请求都处理完成,而新的请求又被拒绝了。这时调度器再次开始接受新请求,Prefill节点的负载又开始上升。
- 之后,这个过程会周期性地重复,导致Prefill和Decoding节点的负载出现反相位的波动。

针对这一问题,月之暗面团队对这种简单的早期拒绝策略进行了修正,提出了基于预测的早期拒绝策略,从而降低节点负载的波动。
这种策略的核心思想是对一段时间后的Decoding节点负载进行预测,并基于预测结果决定是否拒绝请求。
预测可以在请求级别和系统级别两个层面进行,请求级别的预测比较困难,因为要预测单个请求的执行时间;系统级别的预测相对容易一些,只需要预测整体的负载情况。
Mooncake采用的是一种简化的系统级别预测方法,假设每个请求的执行时间服从某个固定分布,据此预测未来一段时间内的负载情况。
实验结果表明,这种基于预测的早期拒绝策略,可以有效缓解负载波动问题。

最终,端到端性能评估结果表明,Mooncake的架构设计和优化策略,有效提高了推理服务性能,尤其在长上下文和真实场景下优势更加显著。
在ArXiv Summarization和L-Eval数据集上,Mooncake的吞吐量比baseline方法vLLM分别提高了20%和40%。

在模拟数据集上,Mooncake的吞吐量最高可达525%,在真实数据集上也可以比vLLM多处理约75%的请求。

过载场景下的性能评估结果则显示,使用基于预测的早期拒绝策略时,拒绝的请求数量从baseline的4183个减少到了3589个,说明系统的请求处理能力得到了提高。

针对未来的发展,论文的另一位作者、清华大学计算机系助理教授章明星表示,从目前的趋势来看,大模型服务的负载会愈发的复杂和多元化,调度会越来越复杂,也会越来越重要。
而对于月之暗面的发展方向,则是由许欣然做了解答——分布式策略的实施,也意味着未来月之暗面的整个系统,将往“算力/$”和“带宽/$”两个方向独立发展,从而对硬件优化更加友好。
论文地址:
https://arxiv.org/pdf/2407.00079
GitHub:
https://github.com/kvcache-ai/Mooncake
参考链接:
[1]https://zhuanlan.zhihu.com/p/705910725
[2]https://zhuanlan.zhihu.com/p/706204757
—完—